
Personal Research on Deep Neural Network Optimization
Dates: Sept. 2021 - Ongoing
Context
I had worked on algorithms for the optimization of single layer neural networks in a previous project (see here). In this project, I wanted to work on deeper neural networks. I first tried to generalize the algorithm to multiple layers, but after a lot of modifications I ended up with a completely different optimization method, which seems to outperform standard optimizers by a large margin (see experiments below).
My algorithms
As this is still an ongoing project that I find promising, I prefer not to disclose the details of my algorithm. However, there are some interesting observations and experiments worth mentioning.
As my method was originally found intuitively, I took some time to back up my intuition with a more theoretical analysis. What was surprising is that although it is a first-order method (in the sense that it does not require computing second order derivatives), it is able to minimize the loss much faster than the standard stochastic gradient descent, even when I force it to have the same step size as the SGD! As gradient descent is optimal when considering the first order approximation of the loss, this suggests that my method somewhat considers a higher order approximation of the loss.
I found some interesting similarities with Newton’s method, but my method is much more efficient as it is a first-order method (Newton’s method is a second-order method, so it requires computing the Hessian matrix).
I have currently tested my method in a few settings, using the CIFAR10 dataset:
- Classification:
- MLP with 3 layers
- CNN with 2 convolutional layers and 2 fully connected layers
- Autoencoder:
- MLP with 4 layers
Although my method takes more time per epoch (4.3s, against 2.6s for Adam), it is able to reach a loss that would take Adam much more epochs to each.
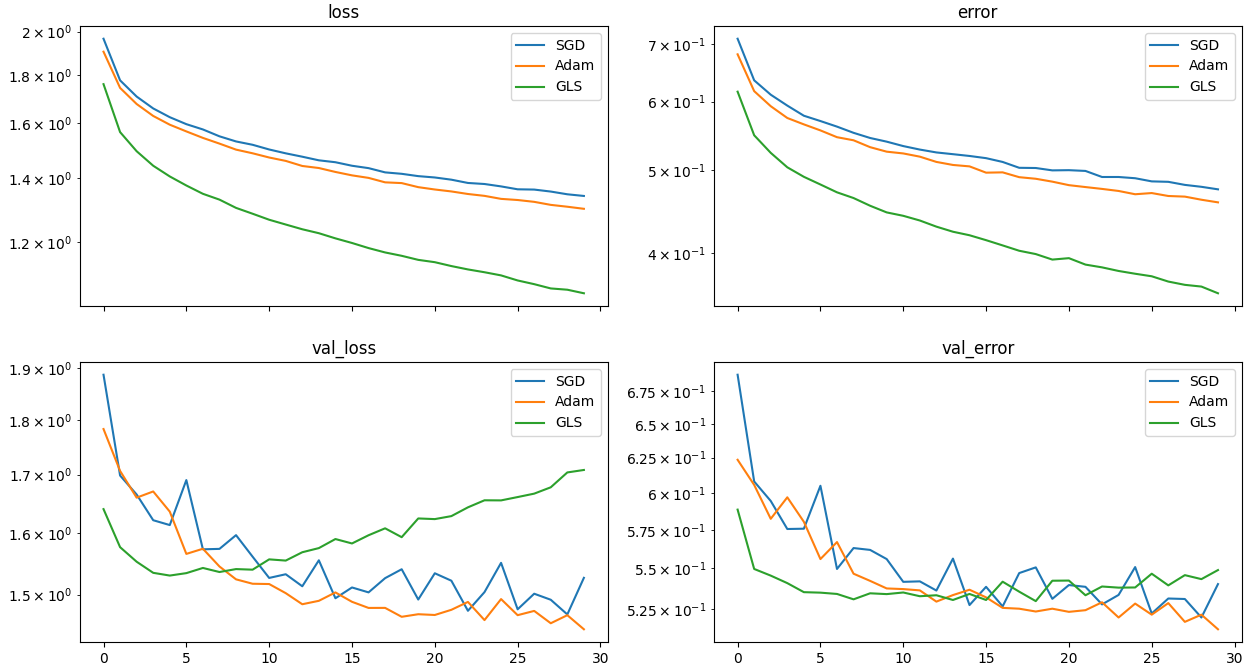
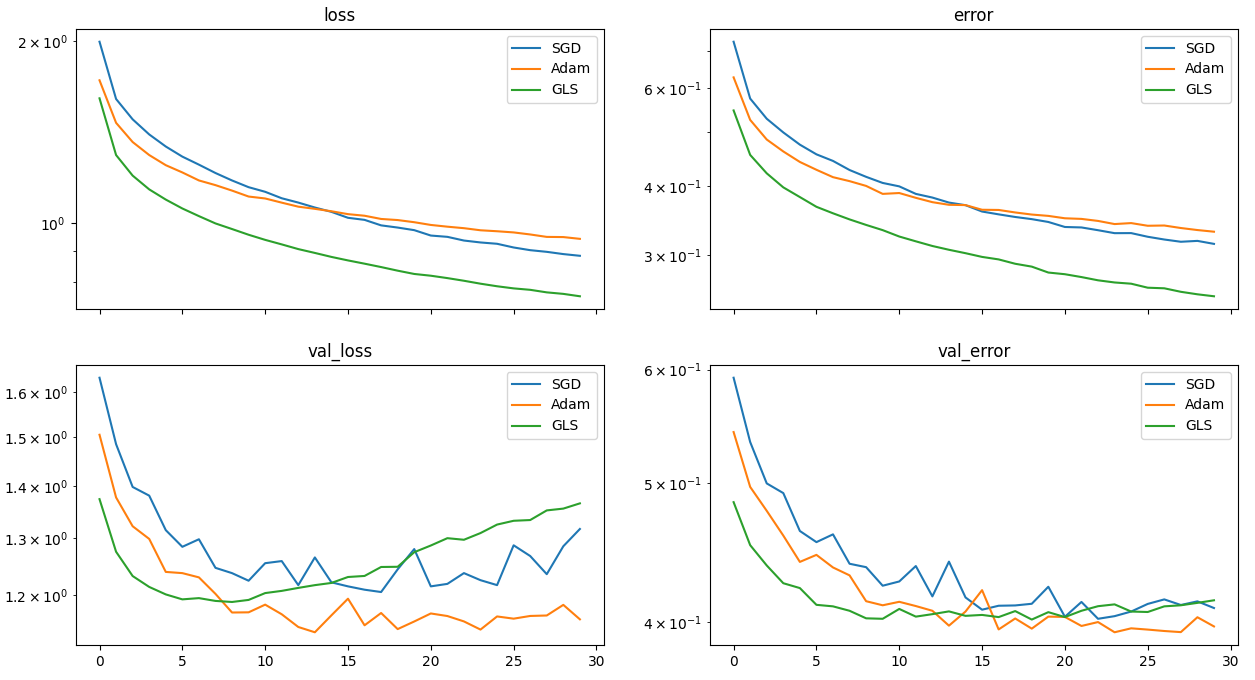
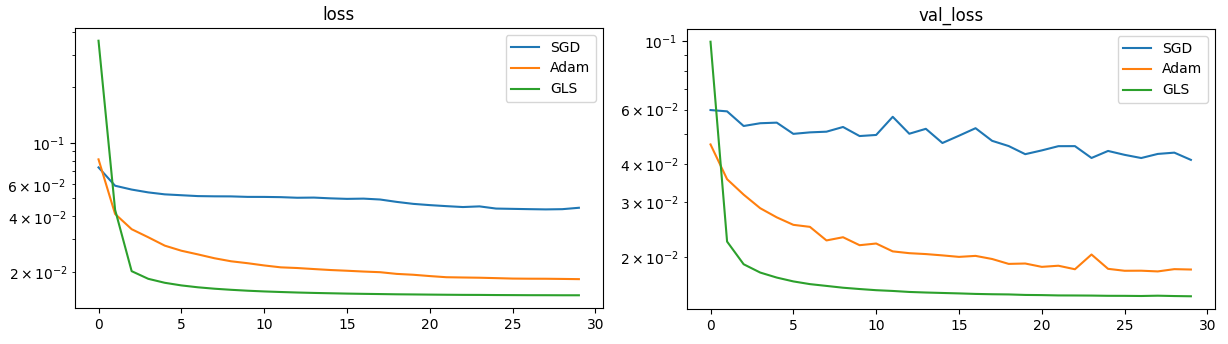
These experiments show promising results as it minimizes the training loss faster than SGD and Adam, but it seems the method leads to worse generalisation on the classification task (the best validation loss reached is higher than that of other optimizers). This is probably due to the implicit regularization of SGD and Adam, which can be seen as a noisy version of my method, that prevents the model from converging to poor local minima. As it is harder for an autoencoder to overfit, the optimizer performs best for this task – and outperforms Adam by several orders of magnitude. This suggests that the method may not be suitable for all tasks, similarly to the fact that SGD is often the best optimizer in computer vision tasks while Adam is better in NLP. I plan to investigate this more in the future.
Other things I plan to do:
- investigate and fix some instability issues when the hyperparameters are not well chosen
- evaluate on more complex models from different fields (e.g. ResNet, language models, etc)
- combine my method with adaptive learning rates (e.g. Adam) and momentum to see if it can further improve the results